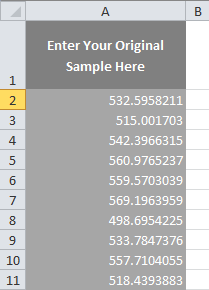
Get a Pareto Chart & Analysis Template Right Here
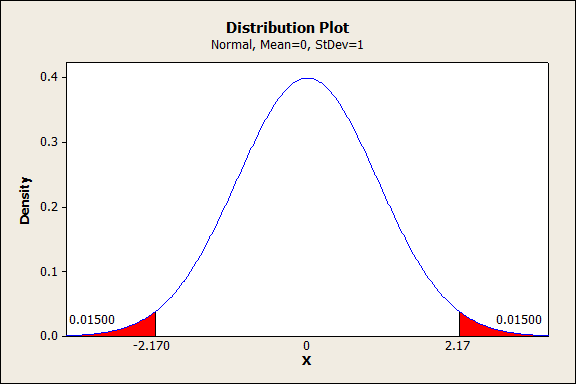
Sometimes, the vast majority of our problems have just a few small causes. Pareto charts, and Pareto analysis, are tools that help us discover which problems are causing most of our defects (or alternatively, which small number of opportunities offer the majority of the payoff). Today, I’ll talk about how to build a Pareto Chart and run [...]